
微服务日志收集
 | 阅读:次
| 阅读:次
为了方便收集,每个服务的日志放到 /logs/服务名称目录下
以Docker部署的服务需要在启动容器时加上参数 -v /宿主机目录:/容器内目录 将日志共享到宿主机

1、Flume
在每台服务器上安装Flume-Agent,每个agent使用ExecSource监听日志文件,AvroSink发送日志,在汇总时使用AvroSource接收日志,FileRollSink落地
agent配置:
log_collection_agent.channels = memoryChannel
log_collection_agent.sinks = logSink
log_collection_agent.sources = fileSource
log_collection_agent.sources.fileSource.channels = memoryChannel
log_collection_agent.sources.fileSource.type = exec
log_collection_agent.sources.fileSource.command = tail -F /home/work/code/saas/bit-saas-api-monitor/logs/api-monitor-20190827-0.log
log_collection_agent.channels.memoryChannel.type = memory
log_collection_agent.channels.memoryChannel.capacity = 1000
log_collection_agent.channels.memoryChannel.transactionCapacity = 50
log_collection_agent.sinks.logSink.channel = memoryChannel
log_collection_agent.sinks.logSink.type = avro
log_collection_agent.sinks.logSink.hostname = 127.0.0.1
log_collection_agent.sinks.logSink.port = 4545
log_collection_agent.sinks.logSink.batch-size = 10
sink端配置:
log_collection_sink_agent.channels = memoryChannel
log_collection_sink_agent.sinks = logSink
log_collection_sink_agent.sources = avroSource
log_collection_sink_agent.sources.avroSource.channels = memoryChannel
log_collection_sink_agent.sources.avroSource.type = avro
log_collection_sink_agent.sources.avroSource.bind = 127.0.0.1
log_collection_sink_agent.sources.avroSource.port = 4545
log_collection_sink_agent.sources.avroSource.batch-size = 10
log_collection_sink_agent.channels.memoryChannel.type = memory
log_collection_sink_agent.channels.memoryChannel.capacity = 1000
log_collection_sink_agent.channels.memoryChannel.transactionCapacity = 50
log_collection_sink_agent.sinks.logSink.channel = memoryChannel
log_collection_sink_agent.sinks.logSink.type = file_roll
log_collection_sink_agent.sinks.logSink.sink.directory = /tmp/flume
log_collection_sink_agent.sinks.logSink.sink.batchSize = 10
2、LogStash
常用 ES + LogStash + Kibana,LogStash 收集,ES存储及更新索引,Kibana展示,暂时不用ES和Kibaba做可视化,只使用LogStash和轻量级的 Filebeat ,在每台服务器上安装Filebeat监听日志文件,汇总时使用LogStash统一收集处理并写入文件
Filebeat配置:
filebeat.inputs:
- type: log
enabled: true
tail_files: true
paths:
- /logs/*/*.log
### Multiline options
multiline.pattern: ^(([0-1]?[0-9]|2[0-3]):([0-5][0-9]):([0-5][0-9]).([0-5][0-9][0-9])).
multiline.negate: true
multiline.match: before

如果有StackTrace打印,LogStash收集的时候会出现顺序错乱,所以需要使用multiline插件把StackTrace日志合并成一行,目前服务的log都是以时间开头,可以判定不是以时间开头的都是StackTrace日志,需要合并到上一行
使用正则判断是否以时间开头
^(([0-1]?[0-9]|2[0-3]):([0-5][0-9]):([0-5][0-9]).([0-5][0-9][0-9])).
如果有日志是其他格式,需要修改匹配规则
output.logstash:
# The Logstash hosts
hosts: ["localhost:4560"]
codec.json:
pretty: true
escape_html: false

LogStash配置:
input {
beats {
port => "4560"
}
}
filter {
mutate {
split => {"source" => "/logs/"}
add_field => {"filepath" => "%{source[-1]}"}
}
mutate {
split => {"filepath" => "/"}
add_field => {"service_name" => "%{filepath[0]}"}
add_field => {"file_name" => "%{filepath[1]}"}
}
}
output {
file {
path => "/tmp/test/%{service_name}/%{[beat][hostname]}/%{filename}"
codec => line { format => "%{message}"}
}
}

LogStash收集到的日志格式入下图:
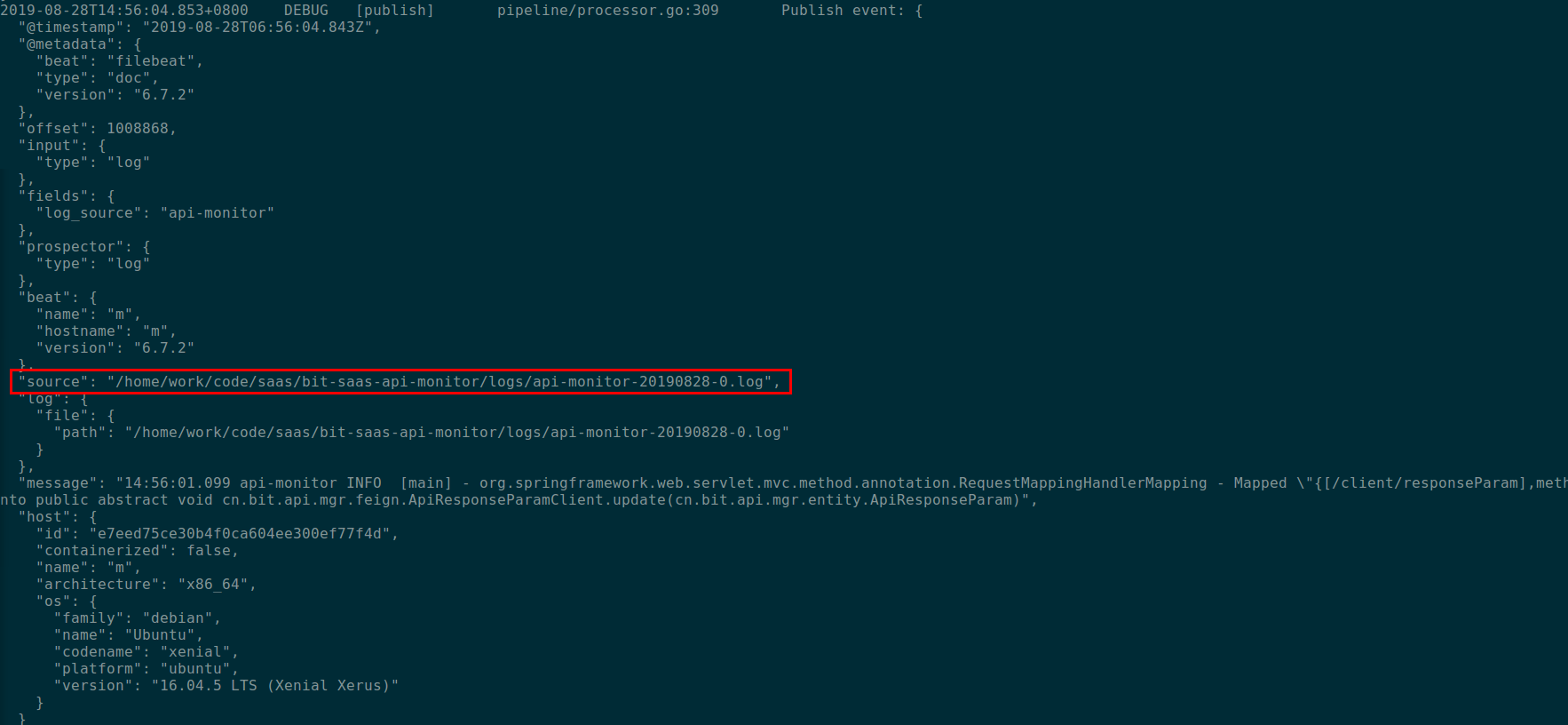
使用LogStash的filter处理收到的日志,对source切分取出服务名和文件名,写文件时拼接路径写到相应的位置
Flume和LogStash对比
1、Flume有事务处理,侧重于数据的传输,可以与Kafka结合使用,对日志做后续分析处理
2、Flume的FileRollSink只能按时间分割文件,不能定制存放目录,查看日志不方便,如果要实现该功能,需要自定义Sink,而LogStash有集成好的插件,可以直接用
3、FileBeat和LogStash功能类似,比LogStash轻量,配置简单,不需要依赖其他环境,占用资源少,Flume相对较重,需要依赖JDK环境,占用资源多
4、目前需要的功能只是将日志简单汇聚,方便查看
所以采用Filebeat + LogStash做日志收集

感谢您的支持,我会继续努力的!




打开支付宝扫一扫,即可进行扫码打赏哦