
K8S节点NodeNotReady问题排查
 | 阅读:次
| 阅读:次
现象:调度服务用的k8s node节点经常会出现NodeNotReady,会导致该节点pod被kill,然后重新拉起来跑一次,影响任务正常运行,而且基本上都是每天 00:00 - 01:00 这个时间段

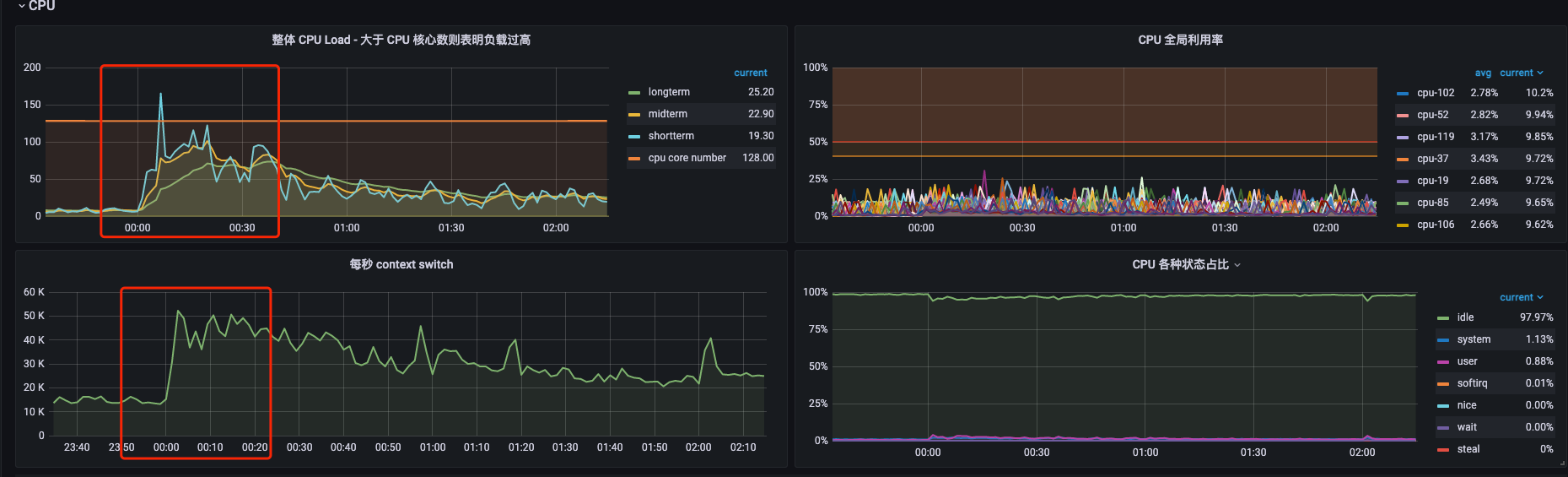
看这几天机器在这个时间段的监控
cpu:
磁盘:
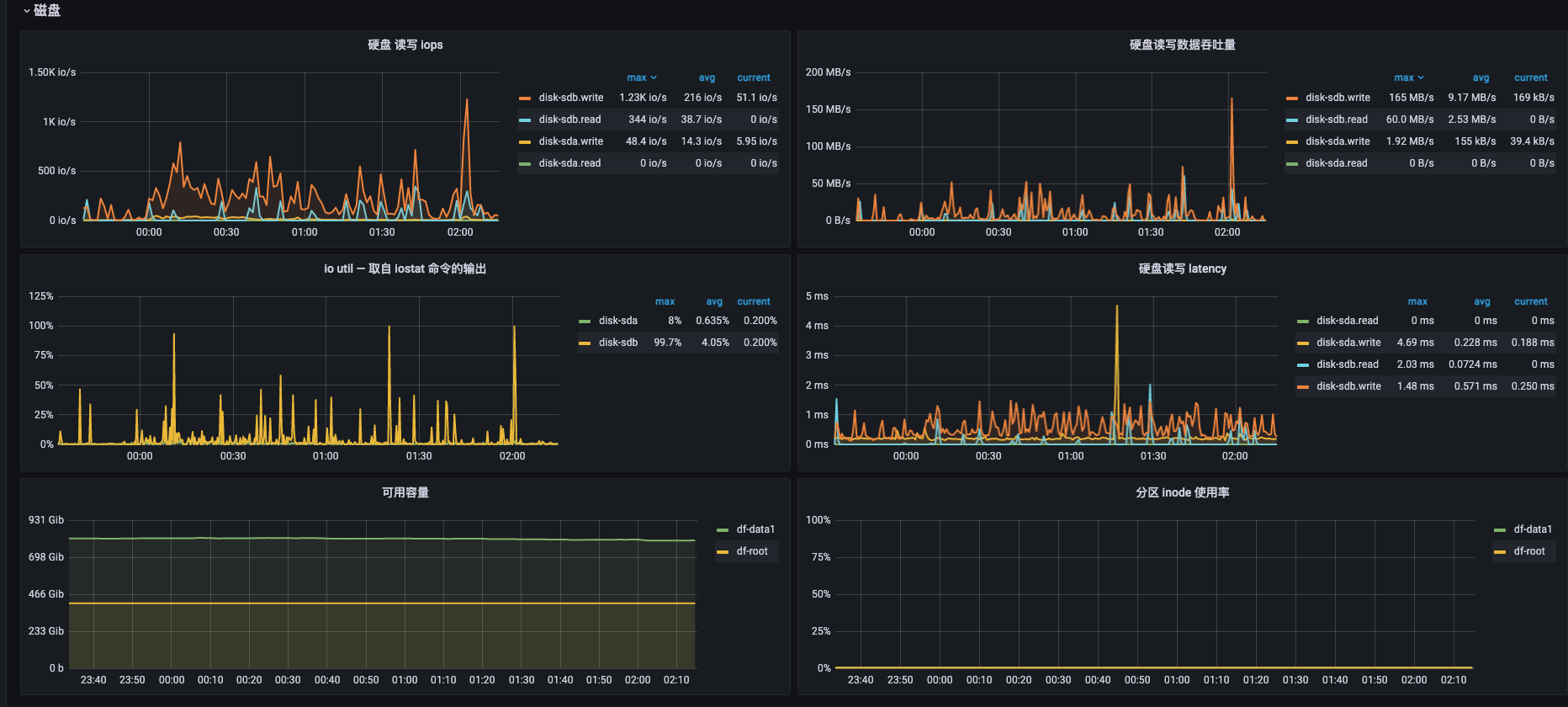
怀疑是任务引用的公共类库太大,导致磁盘io高
统计下任务引用的公共类库大小,查这几台机器在那个时间段跑的任务
是以下实例
worker01: 共180个
53848863,53876058,53878271,53881543,53879733,53859607,53859182,53849607,53849594,53876033,53876152,53849283,53878560,53879299,53879282,53879222,53879279,53814952,53858860,53874661,53880092,53814424,53814072,53849591,53878291,53875739,53878138,53874524,53858671,53878972,53880314,53879763,53879195,53849187,53874681,53849670,53860071,53874511,53859859,53879356,53860273,53874706,53874764,53881567,53849106,53860253,53879192,53882067,53879475,53874772,53860074,53875776,53875673,53875696,53875944,53860104,53874517,53859056,53875478,53881944,53881141,53814567,53880554,53881763,53859756,53876529,53878522,53878349,53881415,53814559,53878489,53859093,53875861,53859446,53860252,53879374,53875562,53814833,53859408,53878906,53875485,53878902,53879845,53880842,53880474,53876150,53881086,53881032,53879994,53881026,53881020,53880996,53876506,53881798,53881725,53880915,53880595,53876328,53881007,53882161,53881007,53881032,53882161,53881020,53880996,53879716,53879684,53876046,53881530,53875993,53879637,53860354,53875842,53860361,53875826,53879342,53875823,53875741,53860272,53859750,53874836,53875026,53874669,53849672,53849680,53814439,53878614,53878238,53878471,53859457,53849559,53859649,53849828,53859734,53878155,53859204,53875392,53859698,53878302,53814613,53814922,53875332,53859566,53814638,53849562,53849558,53849628,53878319,53875371,53875395,53814956,53875430,53875302,53875400,53859143,53849850,53859449,53859033,53814258,53814332,53859094,53814257,53849275,53858967,53849220,53858859,53858873,53814084,53814105,53849138,53858713,53848887,53848850,53848990,53813841,53858699,53858639,53813858,53848827,53861988
以上实例引用的公共类库大小
select
t1.id,
t6.id as instance_id,
t1.job_name,
max(t4.file_path),
max(t5.filesize) / 1024 / 1024 as file_size_mb
from
ares.job t1
left join ares.instance t6 on t1.id = t6.job_id
left join ares.artifact t2 on t1.id = t2.job_id
left join ares.artifact_file t3 on t2.id = t3.artifact_id
left join ares.custom_file t4 on t3.file_id = t4.id
left join ares.dwd_job_artifact_file_size t5 on t5.`path` = t4.file_path
where
t6.id in (53848863,53876058,53878271,53881543,53879733,53859607,53859182,53849607,53849594,53876033,53876152,53849283,53878560,53879299,53879282,53879222,53879279,53814952,53858860,53874661,53880092,53814424,53814072,53849591,53878291,53875739,53878138,53874524,53858671,53878972,53880314,53879763,53879195,53849187,53874681,53849670,53860071,53874511,53859859,53879356,53860273,53874706,53874764,53881567,53849106,53860253,53879192,53882067,53879475,53874772,53860074,53875776,53875673,53875696,53875944,53860104,53874517,53859056,53875478,53881944,53881141,53814567,53880554,53881763,53859756,53876529,53878522,53878349,53881415,53814559,53878489,53859093,53875861,53859446,53860252,53879374,53875562,53814833,53859408,53878906,53875485,53878902,53879845,53880842,53880474,53876150,53881086,53881032,53879994,53881026,53881020,53880996,53876506,53881798,53881725,53880915,53880595,53876328,53881007,53882161,53881007,53881032,53882161,53881020,53880996,53879716,53879684,53876046,53881530,53875993,53879637,53860354,53875842,53860361,53875826,53879342,53875823,53875741,53860272,53859750,53874836,53875026,53874669,53849672,53849680,53814439,53878614,53878238,53878471,53859457,53849559,53859649,53849828,53859734,53878155,53859204,53875392,53859698,53878302,53814613,53814922,53875332,53859566,53814638,53849562,53849558,53849628,53878319,53875371,53875395,53814956,53875430,53875302,53875400,53859143,53849850,53859449,53859033,53814258,53814332,53859094,53814257,53849275,53858967,53849220,53858859,53858873,53814084,53814105,53849138,53858713,53848887,53848850,53848990,53813841,53858699,53858639,53813858,53848827,53861988)
and t4.file_path not like '%.sql'
and t4.file_path not like '%.sh'
-- and t5.filesize / 1024 / 1024 > 20
group by t1.id,t6.id,t1.job_name
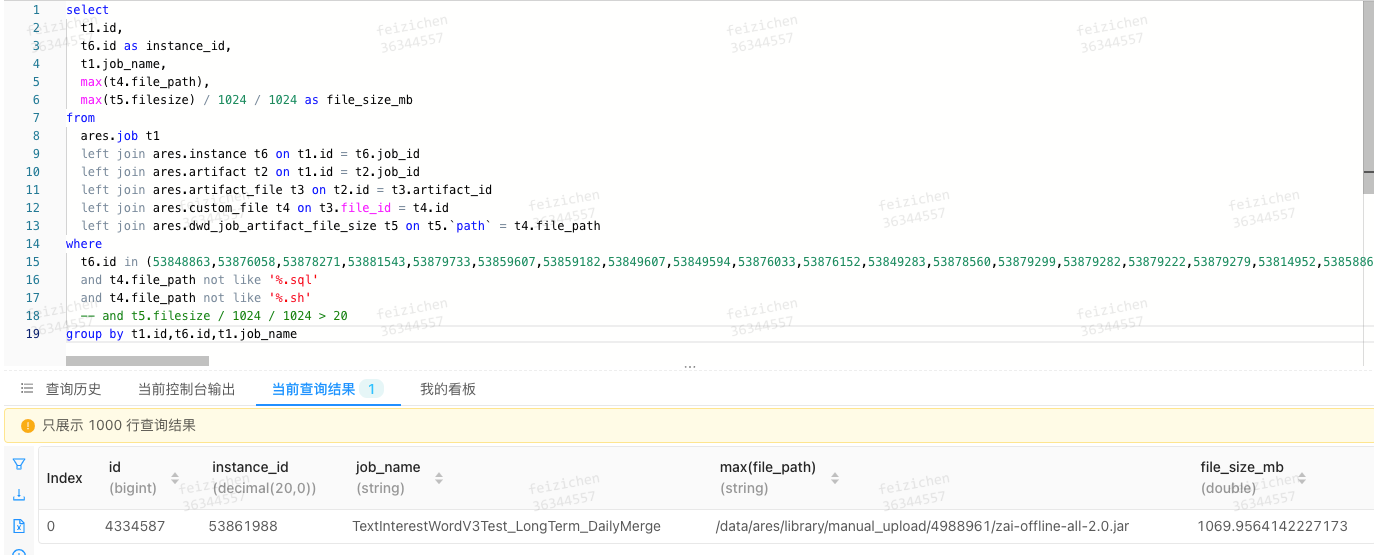
统计出来有引用公共类库的实例并不多,而且jar包也不是很大,看着也不是因为磁盘io的问题
CPU指标都是在那个时间段比较高,磁盘io在其他时间点的指标比出现问题的时间点的指标还高,瓶颈更像是在cpu上
每个节点运行的任务数
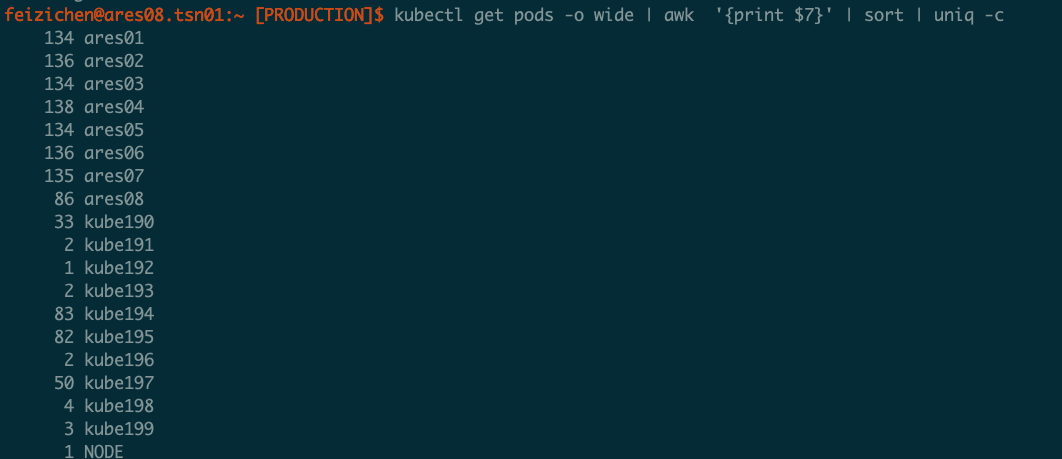
ares01-08节点运行的实例数很不均衡,是因为load太高?
看节点的状态

iostat -xhd 2

top
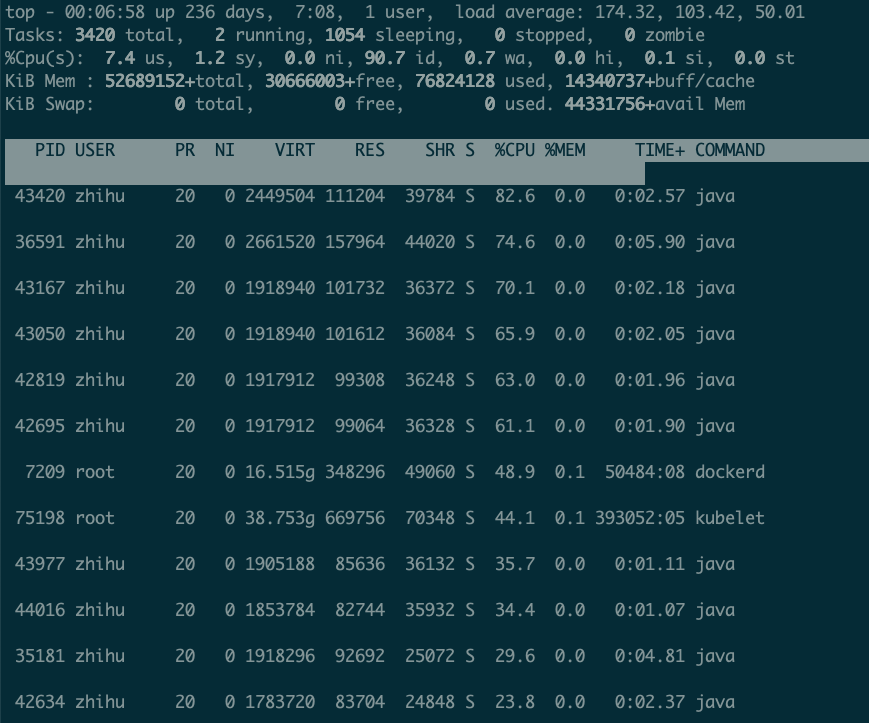
但是load指标和hadoop集群data节点随便两三百的指标比也不是很高,而且每个core的利用率很低,又不太像是卡在cpu的瓶颈上
再看pod的监控,同一时间段,磁盘io,cpuload这些指标,都有其他节点比NodeNotReady节点指标还高,但是正常运行,所以不能只看这些指标下结论是因为cpu还是磁盘的问题
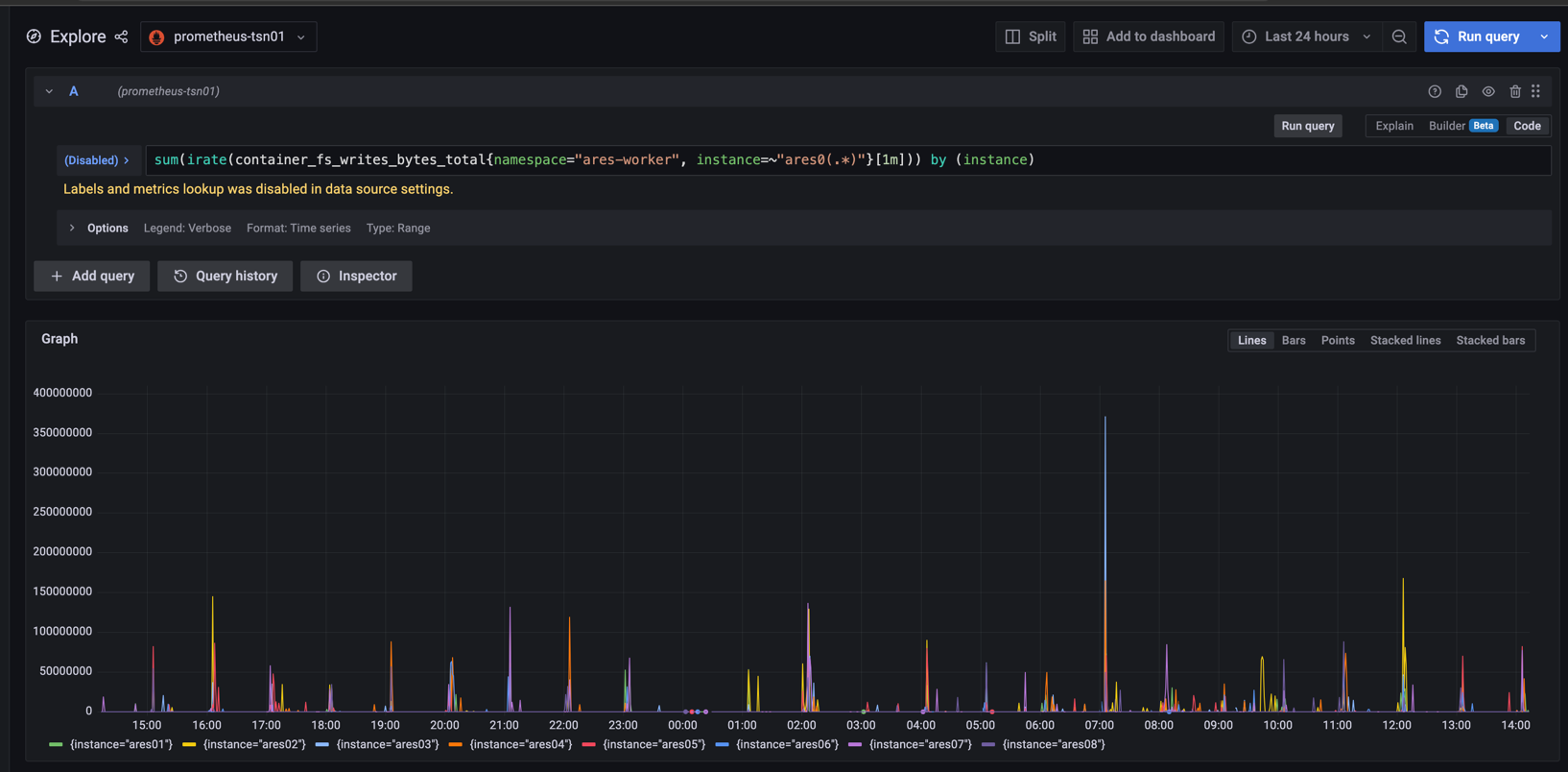
pod相关指标:https://www.huaweicloud.com/guide/productsdesc-bms_18147341
回到问题发生的根本原因,是dockerd进程hang住,那就打火焰图看看是卡在哪个操作上
kublet进程火焰图
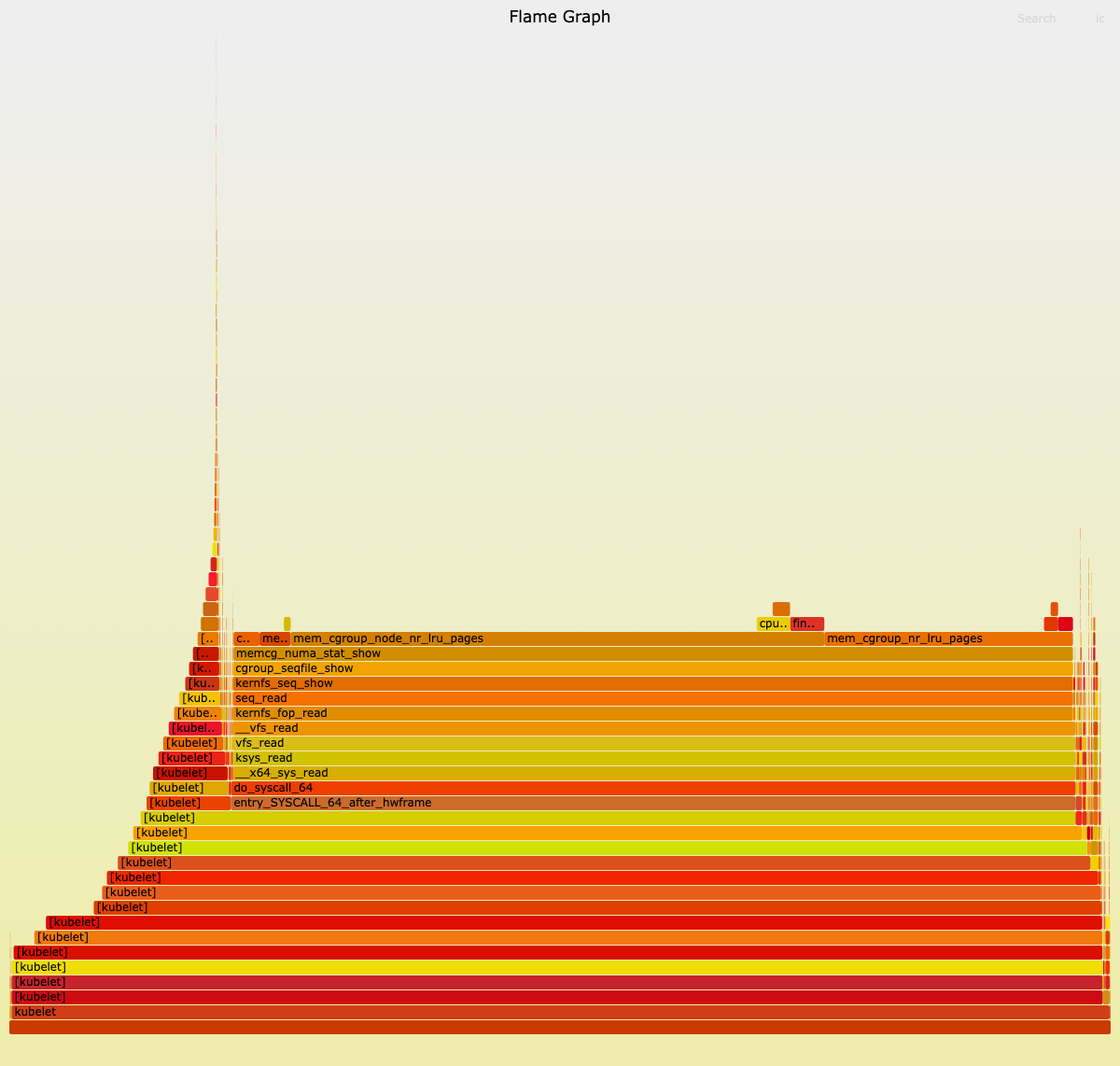
dockerd进程火焰图

看着是卡在 mem_cgroup_node_nr_lru_pages 这个操作上
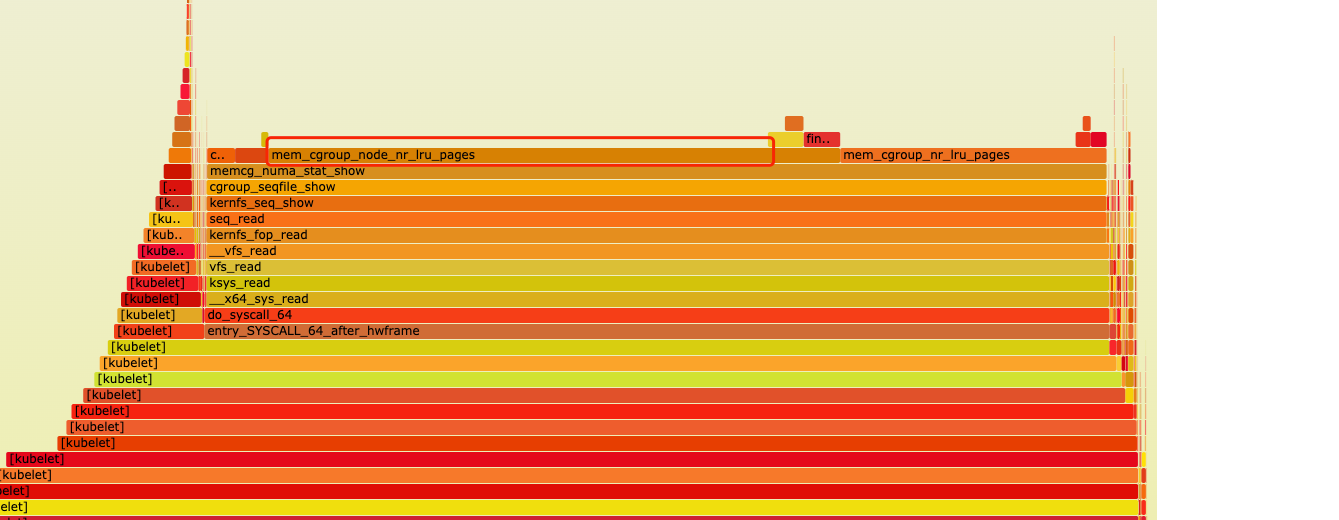
翻到一片文章,和遇到的情况类似https://help.aliyun.com/document_detail/321937.html
看下机器上的cgroup

memory正常cgroup数量不超过2000,但是机器上看都超过7w

但是机器上也没有这么多进程和子线程,memory cgroup泄漏?
其他公司也有类似的问题https://zhuanlan.zhihu.com/p/455530518?utm_medium=social&utm_oi=631605084144930816
临时解决方案就是清理memory cgroup:
echo 3 > /proc/sys/vm/drop_caches
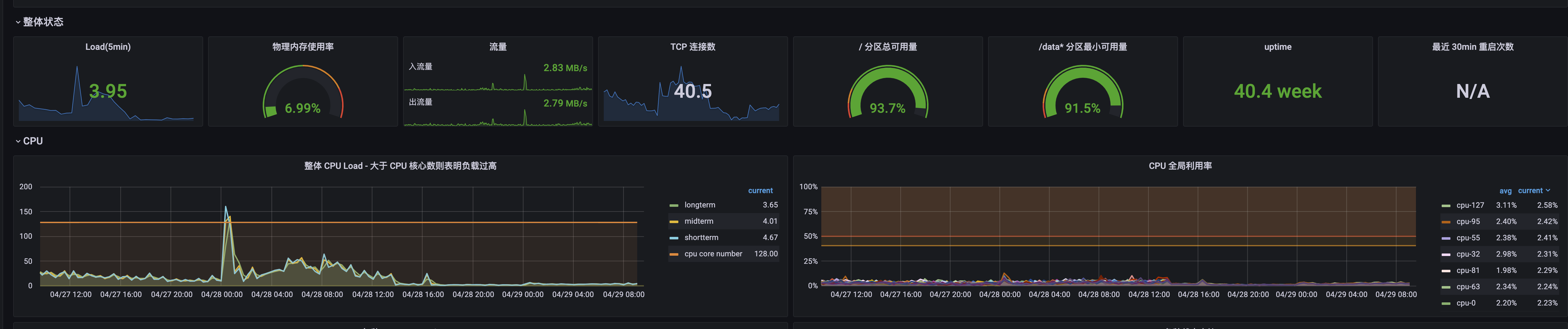
效果:
待解决的问题:
1、cgroup数量为什么这么多? 2、为什么cgroup数量太多会导致dockerd进程hang住?
相关文档:
https://github.com/moby/moby/issues/29638
https://github.com/kubernetes/kubernetes/issues/61937
https://github.com/rootsongjc/kubernetes-handbook/issues/313

感谢您的支持,我会继续努力的!




打开支付宝扫一扫,即可进行扫码打赏哦