
Atlas血缘优化
 | 阅读:次
| 阅读:次
优化血缘上报链路
之前上报血缘逻辑如下
1、先上报所有的实体,Hive,Kafka,HBase, ClickHouse, Doris, HDFS, ES, Chart, DataSet, Report, ReportConfig
2、调用在线服务的接口,获取这些实体的上下游关系,比如任务的依赖,产出表,然后在各个实体间连线(构建边)
3、在边上增加TTL属性,配置定时任务,每隔三天定时全量扫描一次边和实体,找到TTL过期的边进行删除
这种方式会有以下几个问题:
1、全量更新会大量调用线上接口,影响服务稳定性
2、血缘链路长,实时调用接口不会保存版本数据,出现问题不好排查定位是哪个节点
3、离线数仓依赖血缘做治理,只能调用Atlas接口,使用不方便
4、血缘过期需要全量扫描Atlas的数据,非常耗时,而且更新周期长
其实在研究Atlas更新实体的逻辑后,只要修改每个实体的output和input,就会自动更新上下游的血缘关系,将不存在的边删除
所以采用新的上报方式,先离线计算好血缘关系,再全量上报到Atlas
1、同步各个服务的后端数据
2、汇总所有实体
CREATE TABLE `dws_meta.dws_meta_entity_wide_pd`(
`zrn` string COMMENT 'zrn 实体唯一标识',
`id` string COMMENT 'id',
`display_name` string COMMENT '实体名称',
`platform` string COMMENT '平台',
`project_id` string COMMENT '项目组id',
`last_visit_date` string COMMENT '最后访问时间',
`description` string COMMENT '描述',
`owner` string comment 'owner',
`sql` string comment 'sql')
COMMENT '血缘实体'
PARTITIONED BY (
`p_date` string COMMENT '日期YYYY-MM-DD',
`type_name` string COMMENT '实体类型(Hive,Kafka,HBase, ClickHouse, Doris, HDFS, ES, Chart, DataSet, Report, ReportConfig)')
insert overwrite table dws_meta_dev.dws_meta_entity_wide_pd partition(p_date, type_name)
select
distinct
concat('sugarDataModel:', data_model_hash) as zrn,
data_model_hash as id,
data_model_name as display_name,
'Sugar' as platform,
charts_businesses_id as project_id,
'' as last_visit_date,
'' as description,
'2023-11-14' as p_date,
'sugarDataModel' as type_name
from table1
union all
select
distinct
concat('sugarChart:', charts_hash) as zrn,
charts_hash as id,
charts_name as display_name,
'Sugar' as platform,
charts_businesses_id as project_id,
'' as last_visit_date,
'' as description,
'2023-11-14' as p_date,
'sugarChart' as type_name
from table1
union all
select
distinct
concat('sugarReport:', report_hash) as zrn,
report_hash as id,
report_name as display_name,
'Sugar' as platform,
charts_businesses_id as project_id,
charts_last_visit_date as last_visit_date,
'' as description,
'2023-11-14' as p_date,
'sugarReport' as type_name
from table1
union all
select
distinct
concat('sugarReportConfig:', report_hash) as zrn,
report_hash as id,
'' as display_name,
'Sugar' as platform,
charts_businesses_id as project_id,
'' as last_visit_date,
'' as description,
'2023-11-14' as p_date,
'sugarReportConfig' as type_name
from table1
3、构建血缘关系
CREATE TABLE `dws_meta.dws_meta_relation_wide_pd`(
`zrn` string COMMENT 'zrn,实体唯一标识',
`inputs` string COMMENT '输入,多个用「,」分割',
`outputs` string COMMENT '输出,多个用「,」分割')
COMMENT '上报血缘关系'
PARTITIONED BY (
`p_date` string COMMENT '日期YYYY-MM-DD',
`type_name` string COMMENT '实体类型(ares_job, mipha_job, datasync_job, BI_DataSet, reportConfig)')
insert overwrite table dws_meta_dev.dws_meta_relation_wide_pd partition(p_date, type_name)
select
concat('sugarDataModel:', data_model_hash) as zrn,
concat_ws(',', collect_set(concat('dorisTable:doris-infra_pek02:',ck_db_name,':',ck_table_name))) as inputs,
concat_ws(',', collect_set(concat('sugarChart:', charts_hash))) as outputs,
'2023-11-14' as p_date,
'sugarDataModel' as type_name
from table1
group by concat('sugarDataModel:', data_model_hash)
union all
select
concat('sugarReportConfig:', report_hash) as zrn,
concat_ws(',', collect_set(concat('sugarChart:', charts_hash))) as inputs,
concat_ws(',', collect_set(concat('sugarReport:', report_hash))) as outputs,
'2023-11-14' as p_date,
'sugarReportConfig' as type_name
from table1
group by concat('sugarReportConfig:', report_hash)
4、每天把离线表的数据导入到atlas
通过这种上报方式,有以下优点
1、调用一次更新实体的接口就可以更新上下游全部血缘,不需要再全量遍历边做血缘过期,大大降低血缘更新的时长
2、atlas在上下游血缘非常复杂的情况下,通过接口导出血缘非常耗时,有了离线表,可以直接查表导出
3、离线表的数据可以给数据治理提供依据
优化接口耗时
现象:
血缘更新任务非常慢,全量更新大概需要一天的时间,无法做到全量T+1天更新
目前上报的之后Hive和SparkSQL类的任务,大概有2w个,全量更新应该不需要这么长时间
怀疑是调用Atlas更新边的接口太慢,先加日志看看
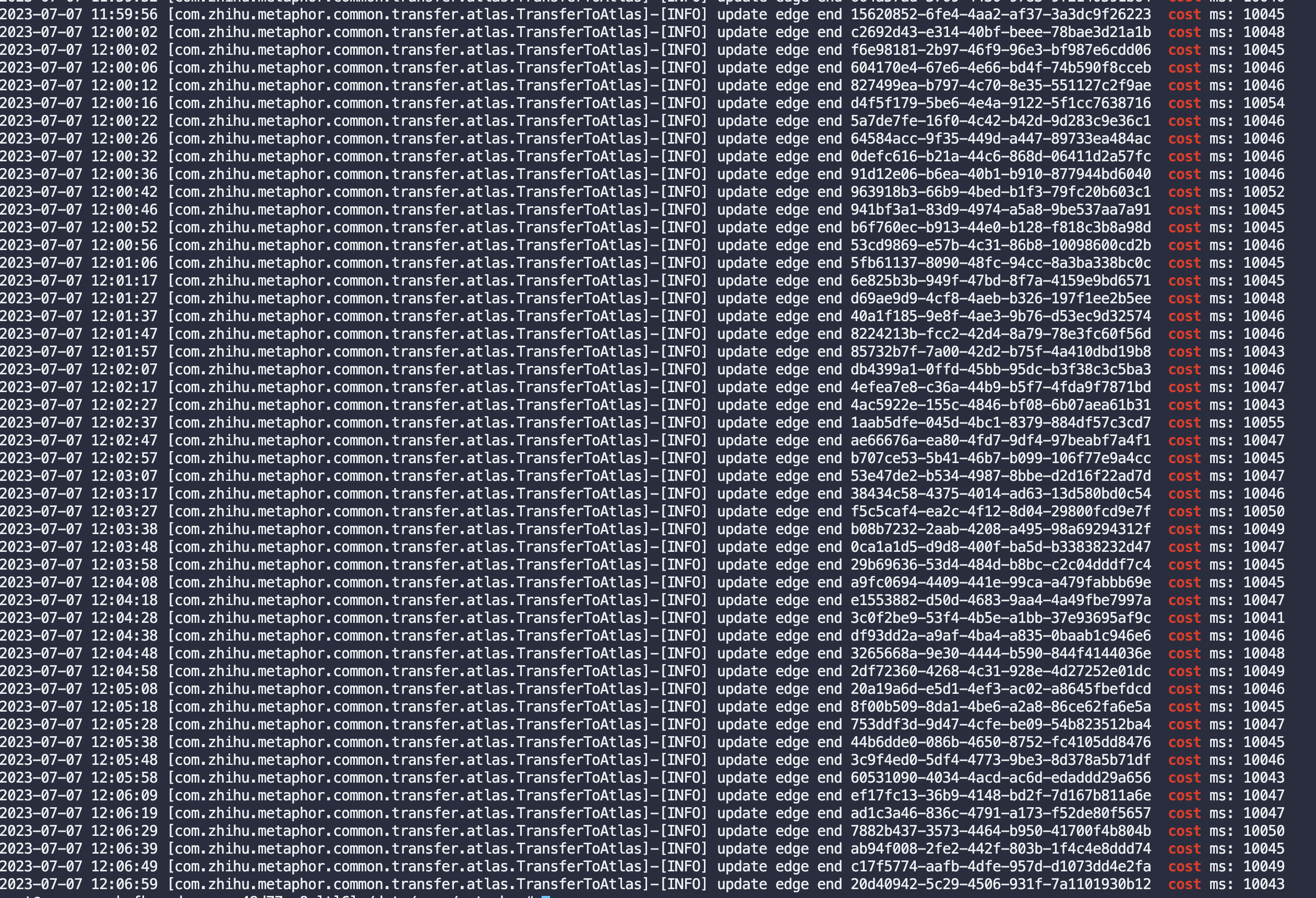
发现每次调用接口都在10s左右,而lock锁的时间配置也是10s

atlas.graph.storage.lock.wait.time具体作用

大概意思就是每次更新后需要持有锁,等待更新成功的时间,默认给的是100ms,但是线上配置是10s,不需要这么长的时间,更新慢应该就是这个配置的问题
修改方式:./janusgraph/bin/gremlin.sh
graph = JanusGraphFactory.open('conf/janusgraph-hbase-es.properties’)
mgmt = graph.openManagement()
mgmt.get('storage.lock.wait-time')
mgmt.set('storage.lock.wait-time', Duration.ofMillis(100))
mgmt.commit()
mgmt.close()
修改配置之后效果
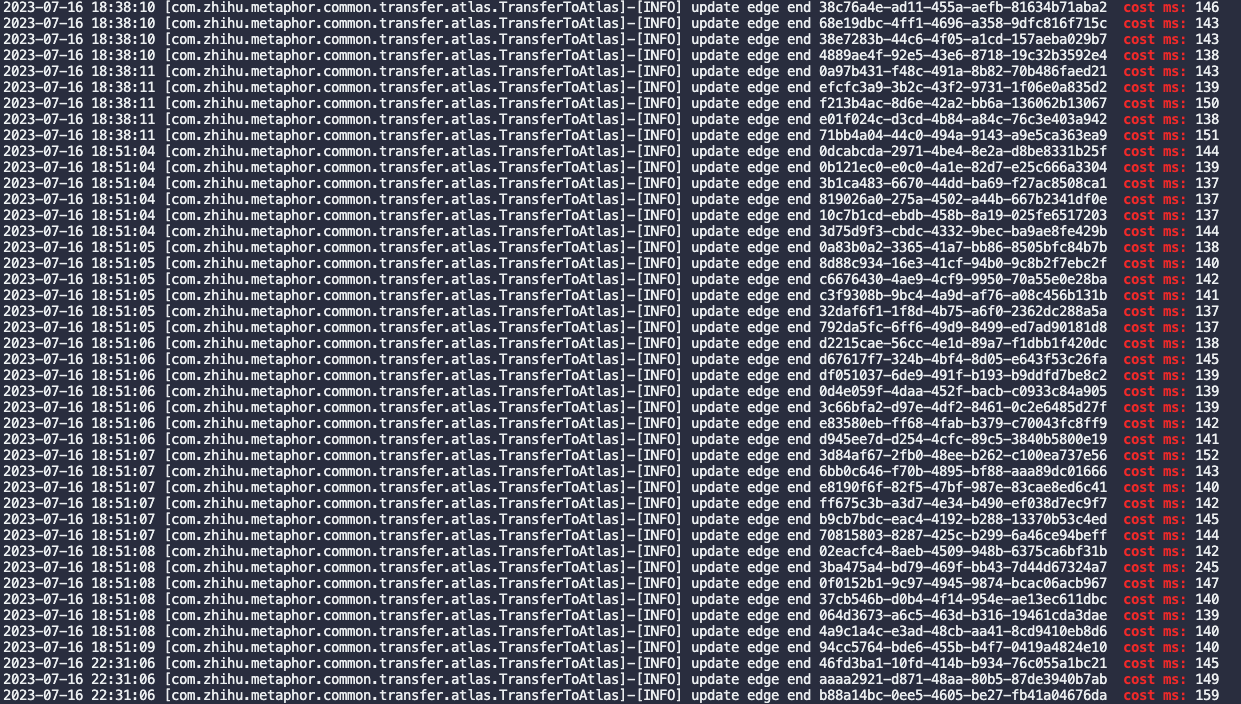
优化之后血缘过期任务执行时长降到3小时,可以做到T+1天更新血缘

感谢您的支持,我会继续努力的!




打开支付宝扫一扫,即可进行扫码打赏哦